
这些应用场景包括让聊天机器人处理产品支持问题,或作为管理日程的个人助理。但如何让小语言模型(SLM)在执行专用的代理式任务时持续以高准确率进行响应,仍然是一个挑战。
这正是微调发挥作用的地方。
Unsloth 是全球范围内应用极为广泛的开源大语言模型(LLM)微调框架之一,为模型定制工作提供了一条简便易操作的实现路径。该框架专门针对 NVIDIA GPU 展开了训练优化,具备高效运行、显存占用低的特点,其适用范围涵盖 GeForce RTX 系列的台式机与笔记本电脑、RTX PRO 工作站,还包括全球体积最小的 AI 超级计算机 DGX Spark。
另一个强大的微调起点是刚刚发布的 NVIDIA Nemotron 3 系列开放模型、数据和代码库。Nemotron 3 引入了目前最高效的开放模型系列,适合用于代理式 AI 的微调。
教会 AI 新招式
微调就像是为 AI 模型进行一次有针对性的训练。通过与特定主题或工作流程相关的示例,模型可以学习新的模式并适应当前任务,从而提升准确性。
为模型选择哪种微调方法,取决于开发者希望对原始模型进行多大程度的调整。根据不同目标,开发者可以采用三种主要的微调方法之一:
参数高效微调(如 LoRA 或 QLoRA):
● 工作原理:仅更新模型的一小部分,以更快、更低成本完成训练。这是一种在不大幅改变模型的情况下提升能力的高效方式。
● 适用场景:几乎适用于所有传统需要完整微调的场景,包括引入领域知识、提升代码准确性、使模型适配法律或科学任务、改进推理能力,或对语气和行为进行对齐。
● 要求:小到中等规模的数据集(100–1,000组示例提示词对)。
完整微调:
● 工作原理:更新模型的所有参数,适用于训练模型遵循特定格式或风格。
● 适用场景:高级应用场景,例如构建 AI 智能体和聊天机器人,这些系统需要围绕特定主题提供帮助、遵循既定的约束规则,并以特定方式进行响应。
● 要求:大规模数据集(1,000+ 组示例提示词对)。
强化学习:
● 工作原理:借助反馈或偏好信号对模型行为加以调整。模型在和环境的交互过程中开展学习,并依托反馈持续优化自身。这属于一种复杂的高级技术,把训练与推理相互交织,同时能够和参数高效微调和完整微调技术结合运用。具体内容可参考Unsloth的强化学习指南。
● 适用场景:提升模型在特定领域(如法律或医学)中的准确性,或构建能够为用户设计并执行动作的自主智能体。
● 要求:一个包含行为模型、奖励模型和可供模型学习的环境的流程。
另一个需要考虑的因素是各种方法的显存需求。下表提供了在 Unsloth 上运行每种微调方法的需求概览。
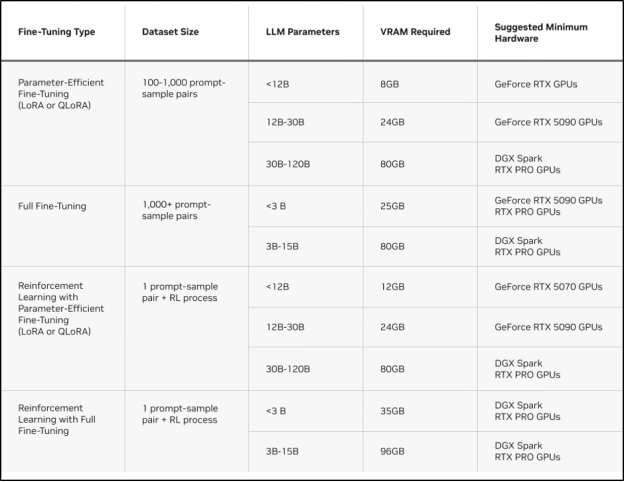
Unsloth:在 NVIDIA GPU 上实现快速微调的高效路径
LLM 微调是一种对内存和计算要求极高的工作负载,在每个训练步骤中都需要进行以十亿次记的矩阵乘法来更新模型权重。这类重型并行计算需要依托 NVIDIA GPU 的强大算力,才能高效、快速地完成。
Unsloth 在这类负载中表现出色,可将复杂的数学运算转化为高效的定制 GPU kernel,从而加速 AI 训练。
Unsloth 能够在 NVIDIA GPU 上把 Hugging Face transformers 库的性能提高到原来的 2.5 倍。这些面向 GPU 的优化措施,再加上 Unsloth 本身易于使用的特点,让微调技术对于更多的 AI 爱好者和开发者来说变得更加容易掌握。
框架专为 NVIDIA 硬件构建并优化,覆盖从 GeForce RTX 笔记本电脑,到 RTX PRO 工作站以及 DGX Spark,在降低显存占用的同时提供巅峰性能。
Unsloth 提供了一系列实用的指南,帮助用户快速上手并管理不同的 LLM 配置、超参数和选项,以及示例 notebook 和分步骤工作流程。
查看链接了解如何在 NVIDIA DGX Spark 上安装 Unsloth。阅读 NVIDIA 技术博客,深入了解在 NVIDIA Blackwell 平台上进行微调和强化学习的相关内容。
现已发布:NVIDIA Nemotron 3 开放模型系列
全新的Nemotron 3开放模型系列涵盖Nano、Super和Ultra三种不同规模,它依托全新的异构潜在混合专家(Mixture-of-Experts, MoE)架构构建而成,是一套兼具领先准确率与高效率的开放模型系列,十分适合用来搭建代理式AI应用。
目前已发布的 Nemotron 3 Nano 30B-A3B 是该系列中计算效率最高的模型,针对软件调试、内容摘要、AI 助手工作流和信息检索等任务进行了优化,具备较低的推理成本。其异构 MoE 设计带来以下优势:
● 推理 token 数量最多减少 60%,显著降低推理成本。
● 支持 100 万 token 的上下文处理能力,使模型在长时间、多步骤任务中能够保留更多信息。
Nemotron 3 Super 是一款面向多智能体应用的高精度推理模型,而 Nemotron 3 Ultra 则适用于复杂的 AI 应用。这两款模型预计将在 2026 年上半年推出。
NVIDIA 于 12 月 15 日还发布了一套开放的训练数据集合集以及先进的强化学习库。Nemotron 3 Nano 的微调现已在 Unsloth 上提供。
Nemotron 3 Nano 现可在 Hugging Face 获取,或通过 Llama.cpp 和 LM Studio 进行体验。
DGX Spark:紧凑而强大的 AI 算力引擎
DGX Spark 支持本地微调,将强大的 AI 性能集成在紧凑的桌面级超级计算机形态中,让开发者获得比普通 PC 更多的内存资源。
DGX Spark 依托 NVIDIA Grace Blackwell 架构构建,FP4 AI 性能峰值可达 1 PFLOP,同时搭载 128GB CPU-GPU 统一内存,助力开发者在本地开展更大规模模型的运行、更长上下文窗口的处理以及更高负载的训练任务。
在微调方面,DGX Spark 可实现:
●支持更大规模的模型。参数规模超过 30B 的模型往往会超出消费级 GPU 的VRAM 容量,但可以轻松运行在 DGX Spark 的统一内存中。
●支持更高级的训练技术。完整微调和基于强化学习的工作流对内存和吞吐量要求更高,在 DGX Spark 上运行速度显著更快。
●本地控制,无需云端排队。开发者可以在本地运行高计算负载任务,无需等待云端实例或管理多个环境。
DGX Spark 的优势不止体现在大语言模型(LLM)领域。高分辨率扩散模型往往对内存的需求超出普通桌面系统的承载能力。而凭借对 FP4 格式的支持以及大容量的统一内存,DGX Spark 能够在短短几秒内完成 1000 张图像的生成,同时为创意类或多模态的工作流提供更出色的持续吞吐量表现。
下表展示了在 DGX Spark 上对 Llama 系列模型进行微调的性能表现。
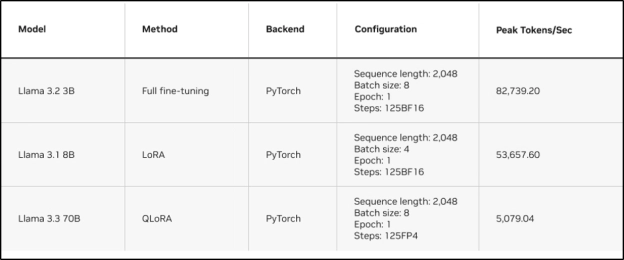
随着微调工作流的不断发展,全新的 Nemotron 3 开放模型系列为 RTX 系统和 DGX Spark 提供了可扩展的推理能力与长上下文性能优化。
#别错过 — NVIDIA RTX AI PC 的最新进展
FLUX.2 图像生成模型现已发布,并针对 NVIDIA RTX GPU 进行优化
Black Forest Labs 推出的新模型支持 FP8 量化,可降低显存占用并将性能提升40%。
Nexa.ai 通过 Hyperlink 为 RTX PC 扩展本地 AI,实现代理式搜索
这款全新的本地搜索智能体能够让检索增强生成(RAG)的索引速度提高3倍,LLM推理速度提升2倍——原本一个1GB的高密度文件夹索引大约需要15分钟,现在仅需4到5分钟就能完成。此外,DeepSeek OCR已通过NexaSDK以GGUF格式支持本地运行,在RTX GPU上可即插即用,轻松解析图表、公式以及多语言PDF文件。
Mistral AI 发布全新模型家族,并针对 NVIDIA GPU 进行优化
全新的 Mistral 3 模型从云端到边缘端均经过优化,可通过 Ollama 和 Llama.cpp 进行快速的本地实验。
Blender 5.0 正式发布,带来 HDR 色彩与性能提升
本次版本新增了ACES 2.0广色域/HDR色彩支持,还加入了NVIDIA DLSS技术,这项技术能让毛发与皮毛的渲染速度提升最高5倍;另外,版本对大规模几何体的处理能力进行了改进,同时也为Grease Pencil添加了动态模糊效果。




